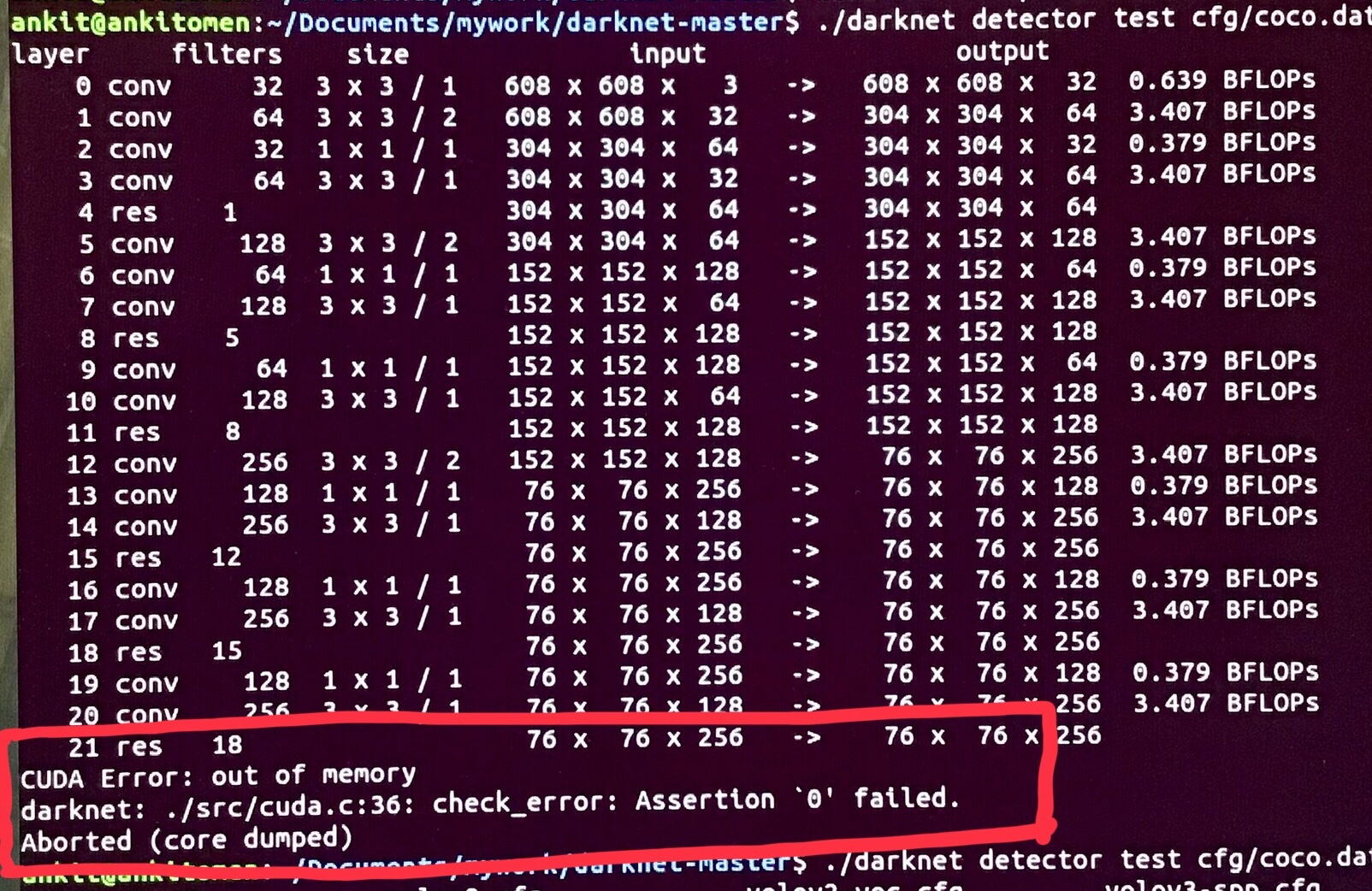
Region-Convlutional Neural Networks (R-CNN) are another State-of-art Detection and Localization Algorithms developed by Ross Grishick, Jeff Donahue, Trevor Darrell, Jitendra Malik.
A significant progress in the domain of object recognition and localization was seen mainly because of Low-Level feature extractors life SIFT and HOG ( a semi-local orientation histograms), while R-CNNs came with the idea of Multi-level, multi-stage Feature Extraction. R-CNN were supposed to improve mAP by 50% relative to the result on VOC-2012, therefore achieving mAP of 62.4%. It brought with itself 2 ideas :
1. For better localization and object segmentation, applying CNNs to a bottom-up Region Proposals. 2. Supervised pre-training for Auxillary tasks followed by domain specific fine tuning.
Unlike a Classification problem, Object Detection requires localization of objects within an image, for which we have multiple approaches :
1. Framing Detection as a Regression problem and Use of anchor Boxes (YOLO) 2. A sliding window technique 3. Recognition using Regions, (R-CNN method)
- This R-CNN system generates 2000 category independent Region Proposals at Test time for an Input Image (the base paper uses Selective Search method for region proposal).
Other Methods of region proposal are :
>> Objectness[1]; category-independent object proposals[2]; constraint parametric mini-cuts (CPMC)[3]; multi-scale combinatorial grouping[4]; mitotic cells obtained by applying CNN to regularly spaced square crops[5] - Feature Vector Extraction from each region proposal using CNN
- Classification of each region with category specific Linear SVM
Base paper also talks about the challenge of scarce labelled data, is using Supervised pre-training on a Large auxiliary dataset followed by domain specific fine tuning on small (Pascal) is effective for Learning high-capacity CNNs

Feature Extraction in R-CNN
In the base implementation, features of fixed length are extracted from Each region proposals using a CNN architecture.
Here most experiments used Caffe implementation of CNN which is described by TorontoNet (Krizhevksy et-al)[6]. Experimentation with OxfordNet (Simonyan & Zisserman)[7] was also made.
Feature Vectors are 4096 dimensional .
We first convert Image Data in a region proposal into a fixed input size of S x S pixel size.
For TorontoNet S = 227, while for OxfordNet S = 224.
Training
CNN was pre-trained on Auxilary Dataset (ILSVRC2012) using image-level annotations (bounding box is not available for this data). Pre-training was performed using open source caffe CNN library.
Selective Search Algorithm :
> By initial sub-segmentation of images, generate 2000 Region Proposals
> Using greedy Algorithm, combine similar regions to larger ones
> Using this final generated region as candidate region proposal
Problems with R-CNN
- Training of the model requires a considerate amount of time as we have to classify 2000 region proposal per image.
- Not suited for Real -Time application due to above reason
Scaling and Improvement to R-CNN
- He et-al improves R-CNN efficiency by sharing, computation through a feature pyramid allowing for detection at few frames per sec. (SSPnet)
- Dominant approach to object detection was sliding-window detectors. The selective-search algorithm of Van-de-Sande popularized the multiple segmentation approch by showing strong result on PASCAL object detetction. This is an Active Search Area now :
a) Edge boxes: outputs high quality rectangular box proposal quickly (0.3s/img)
b) BING: generates box proposal at 3ms/img.
FAST R-CNN
Fast R-CNN builds up on the work of R-CNN.
The major improvements that were made to the R-CNN model for detection significantly improved both Time and Performance so much so that Fast R-CNN is 9 times faster than R-CNN at training and 213 times faster at Testing.
Architectural modifications
- Instead of individual Region proposals being fed to CNN, complete image is fed as an Input for feature extraction.
- From this feature map region proposals are extracted using Selective Search Algorithm and using ROI pooling they are reshaped into fixed size.
- this reshaped regions are fed to the (fully connected) FC layer.
- A softmax layer is used to predict the class of proposed region and values of bounding box instead of SVM in R-CNN
Therefore major reason for the fastness of this Architecture can be correlated to the fact that we do not have 2000 region proposals to be fed to a CNN every time.
FASTER R-CNN
REFERENCES
[1] : B. Alexe, T. Deselaers, and V. Ferrari, “Measuring the objectness of image windows,” TPAMI, 2012. [2] : I. Endres and D. Hoiem, “Category independent object proposals,” in ECCV, 2010. [3] : J. Carreira and C. Sminchisescu, “CPMC: Automatic object segmentation using constrained parametric min-cuts,” TPAMI, 2012. [4] : P. Arbel´aez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik, “Multiscale combinatorial grouping,” in CVPR, 2014. [5] : D. Cires¸an, A. Giusti, L. Gambardella, and J. Schmidhuber, “Mitosis detection in breast cancer histology images with deep neural networks,” in MICCAI, 2013. [6] : A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet classification with deep convolutional neural networks,” in NIPS, 2012. [7] : K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in ICLR, 2015.


 D:/opencv/gstremer/1.0/x86_64/include/glib-2.0
D:/opencv/gstremer/1.0/x86_64/include/glib-2.0