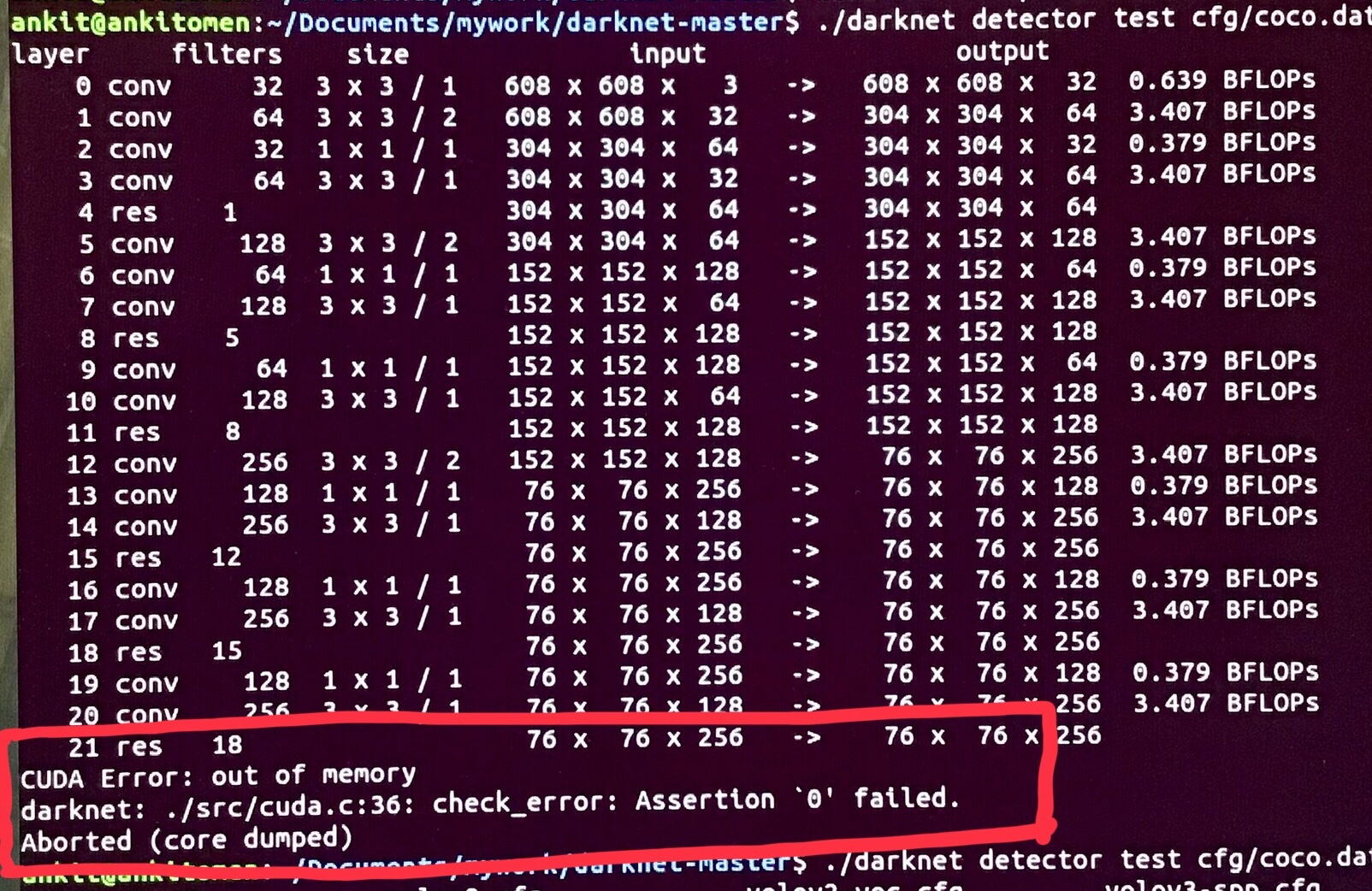
As we have already talked about the evolution of Neural nets in our previous posts, we know that since their inception in 1970’s, these Networks have revolutionized the domain of Pattern Recognition.
The Networks developed in 1970’s were able to simulate a very limited number of neurons at any given time, and were therefore not able to recognize patterns involving higher complexity.
However, by the end of mid 1980’s these networks could simulate many layers of neurons, with some serious limitations – that involved human involvement (like labeling of data before giving it as input to the network & computation power limitations ). This was possible because of Deep Models developed by Geoffery Hinton.
Hinton in 2006, revolutionized the world of deep learning with his famous paper ” A fast learning algorithm for deep belief nets ” which provided a practical and efficient way to train Supervised deep neural networks.
In 1985 Hinton along with Terry Sejnowski invented an Unsupervised Deep Learning model, named Boltzmann Machine. These are Stochastic (Non-Deterministic) learning processes having recurrent structure and are the basis of the early optimization techniques used in ANN; also known as Generative Deep Learning model which only has Visible (Input) and Hidden nodes.
OBJECTIVE
Boltzmann machines are designed to optimize the solution of any given problem, they optimize the weights and quantity related to that particular problem.
It is of importance to note that Boltzmann machines have no Output node and it is different from previously known Networks (Artificial/ Convolution/Recurrent), in a way that its Input nodes are interconnected to each other.
The below diagram shows the Architecture of a Boltzmann Network:
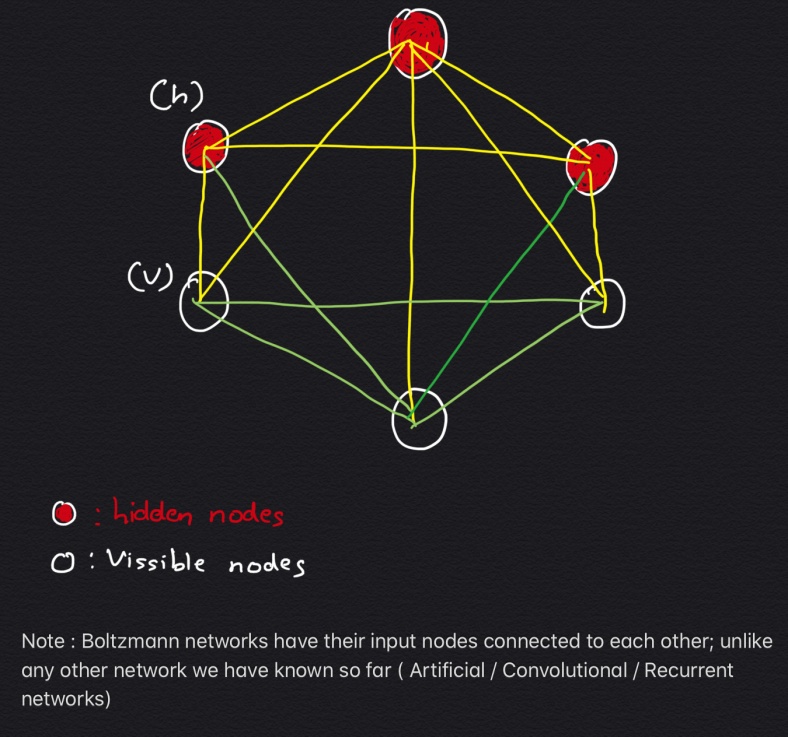
All these nodes exchange information among themselves and self-generate subsequent data, hence these networks are also termed as Generative deep model.
These Networks have 3 visible nodes (what we measure) & 3 hidden nodes (those we don’t measure); boltzmann machines are termed as Unsupervised Learning models because their nodes learn all parameters, their patterns and correlation between the data, from the Input provided and forms an Efficient system. This model then gets ready to monitor and study abnormal behavior depending on what it has learnt.
This model is also often considered as a counterpart of Hopfield Network, which are composed of binary threshold units with recurrent connections between them.
Types of Boltzmann Machines
- EBM ( Energy Based models )
- RBM (Restricted Boltzmann Machines )
Energy – Based Models
EBMs can be thought as an alternative to Probabilistic Estimation for problems such as prediction, classification, or other decision making tasks, as their is no requirement for normalisation.
Formula for Boltzmann Distribution

This equation is used for sampling distribution memory for Boltzmann machines, here, P stands for Probability, E for Energy (in respective states, like Open or Closed), T stands for Time, k: boltzmann constant. Therefore for any system at temperature T, the probability of a state with energy, E is given by the above distribution.
Note: Higher the energy of the state, lower the probability for it to exist.
In the statistical realm and Artificial Neural Nets, Energy is defined through the weights of the synapses, and once the system is trained with set weights(W), then system keeps on searching for lowest energy state for itself by self-adjusting.
These EBMs are sub divided into 3 categories:
- Linear Graph Based Models ( CRF / CVMM / MMMN )
- Non-Linear Graph Based models
- Hierarchical Graph based models
Conditional Random Fields (CRF) use a negative log-likelihood loss function to train linear structured models.
Max-Margin Markov Networks(MMMN) uses Margin loss to train linearly parametrized factor graph with energy func- optimised using SGD.
Training/ Learning in EBMs
The fundamental question that we need to answer here is ” how many energies of incorrect answers must be pulled up before energy surface takes the right shape. ”
Probabilistic learning is a special case of energy based learning where loss function is negative-log-likelihood. The negative log-likelihood loss pulls up on all incorrect answers at each iteration, including those that are unlikely to produce a lower energy than the correct answer. Therefore optimizing the loss function with SGD is more efficient than black-box convex optimization methods; also because it can be applied to any loss function- local minima is rarely a problem in practice because of high dimensionality of the space.
Restricted Boltzmann Machines & Deep Belief Nets
Shifting our focus back to the original topic of discussion ie
Deep Belief Nets, we start by discussing about the fundamental blocks of a deep Belief Net ie RBMs ( Restricted Boltzmann Machines ).
As Full Boltzmann machines are difficult to implement we keep our focus on the Restricted Boltzmann machines that have just one minor but quite a significant difference – Visible nodes are not interconnected – .
RBM algorithm is useful for dimensionality reduction, classification, Regression, Collaborative filtering, feature learning & topic modelling.
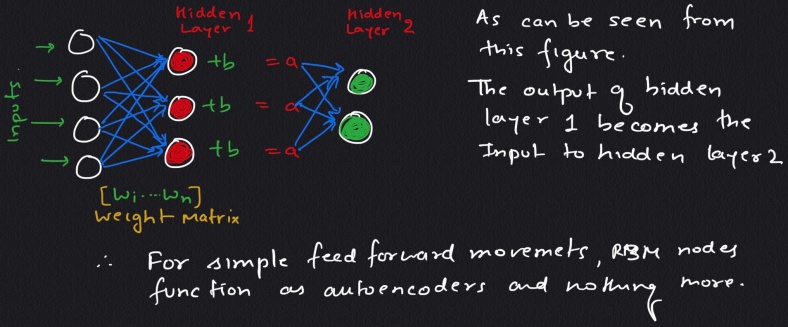
The important question to ask here is how these machines reconstruct data by themselves in an unsupervised fashion making several forward and backward passes between visible layer and hidden layer 1, without involving any further deeper network.
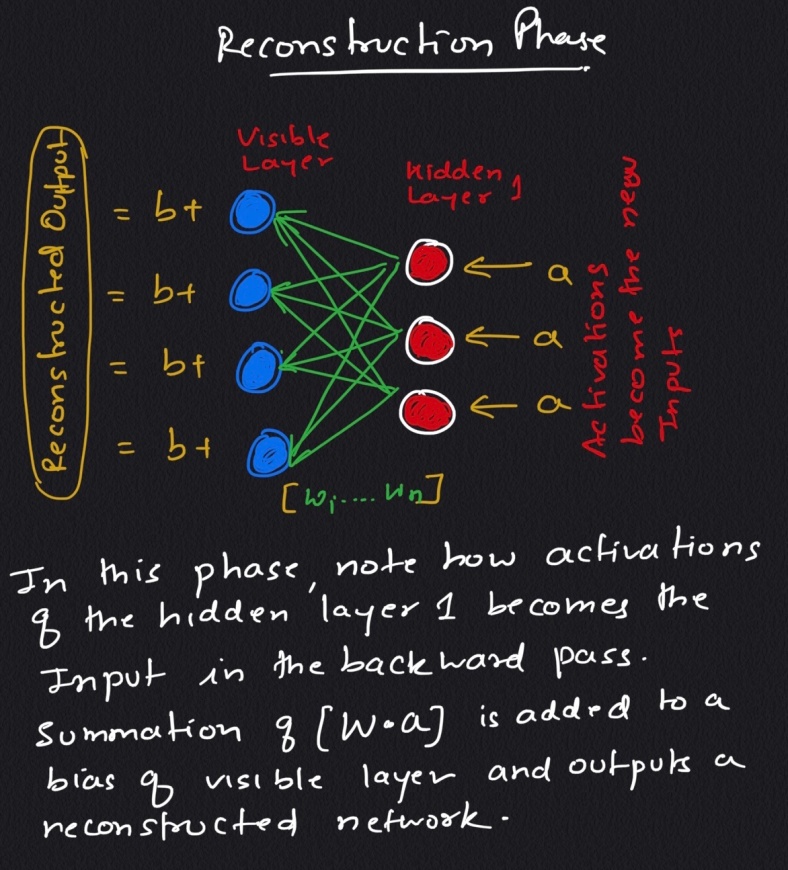
note : the output shown in the above figure is an approximation of the original Input.
Since the weights are randomly initialized, the difference between Reconstruction and Original input is Large.
It can be observed that, on its forward pass, an RBM uses inputs to make predictions about node activation, or the probability of output given a weighted x: p(a|x; w). But on its backward pass, when activations are fed in and reconstructions of the original data, are spit out, an RBM is attempting to estimate the probability of inputs x given activations a, which are weighted with the same coefficients as those used on the forward pass. This second phase can be expressed as p(x|a; w). Together giving the joint probability distribution of x and activation a .
Reconstruction is making guesses about the probability distribution of the original input; i.e. the values of many varied points at once. This is known as generative learning, and this must be distinguished from discriminative learning performed by classification, ie mapping inputs to labels.
Conclusions & Next Steps
You can interpret RBMs’ output numbers as percentages. Every time the number in the reconstruction is not zero, that’s a good indication the RBM learned the input.
It should be noted that RBMs do not produce the most stable, consistent results of all shallow, feedforward networks. In many situations, a dense-layer autoencoder works better. Indeed, the industry is moving toward tools such as variational autoencoders and GANs.